







Web Scraping is the latest method of collecting online information. The term refers to the automated process of accessing websites and downloading specific info, such as prices. Web scraping, which enables the production of large, customized datasets at low cost, is already being used for research and commercial purposes in a variety of fields, including marketing, industrial organizations, and consumer price index measurement.
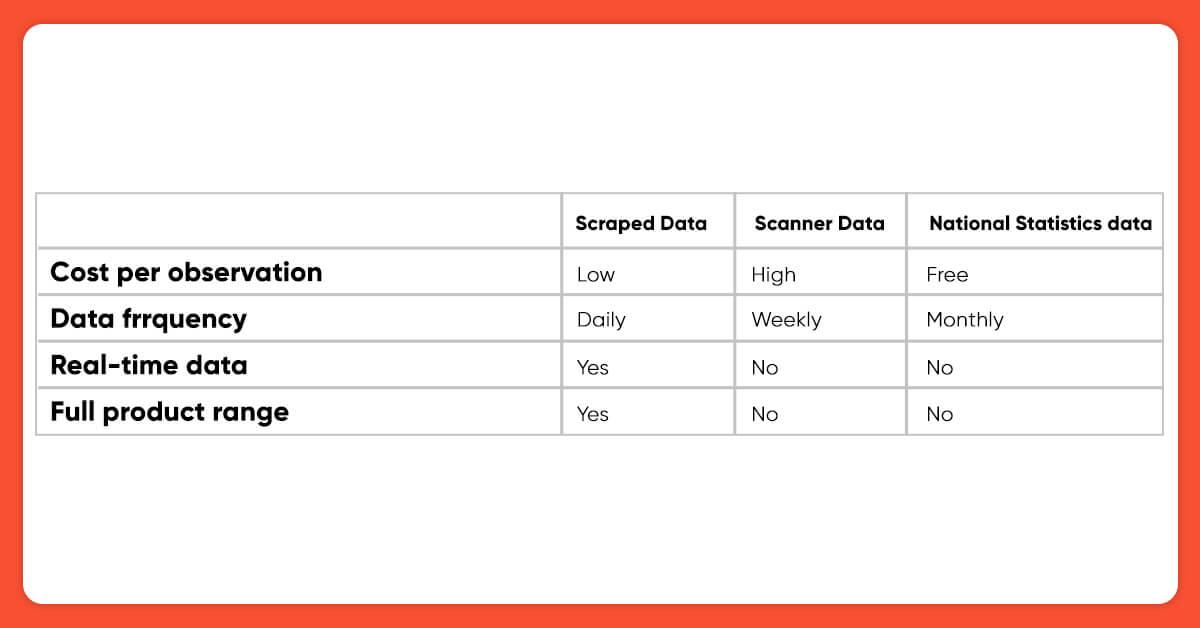
This data collection technique, however, has received little attention in food price research. In agricultural investment and food system analysis, we primarily rely on more conventional data sources of consumer spending, such as official price indices or retail scanner data. However, there are several issues associated with these data sources.
Official prices and price indices for goods, sections such as food, or the entire economy are typically published monthly or quarterly, with some press release delay. The accessibility of lengthy time series and the availability of public data from government agencies are appealing for scientific purposes. However, one must rely on official sources for accurate results, weighting, and clustering. Because no entrance to original data is normally granted, it is impossible to spot errors or even dirty tricks.
Technical Process of Building Web Scraper
There are various methods to develop a web scraper and probably, there is no single size that will fit in all approach. You will need a script that will provide access to the websites hosting the data, finding the relevant information, previously defining elements and then downloading and storing them in structured data sets. In addition, data such as package size, customer ratings, categories, country of origin, etc. can be included.
Web ScrapingWeb CrawlingMethodAutomatic requests web documents and gather data from themRepetitively finds and fetches hyperlinks initiating from a list of initial URLs.Target informationPre-defining information on particular websitesURLs that will access information, depending on search requestOutputDownload the information in the required formatIndexed hyperlinks, that are stored in databaseUsageData gatheringAs hoc requests
According to the theory, the code will imitate a web user, navigating through the various websites, and scraping the pre-defined data. For maintaining a moderate rate of the traffic on websites, this download must happen with some time delay between the requests.
Some programming languages, including Python and R, even have pre-programmed libraries for this reason. Even though such code elements are certainly useful as building blocks, there is always the necessity adjust the script towards the specific webpage, depending on how the website is set up, the page structure, authentication requirements, and so on. Additionally, because many websites use reactive elements, simple HTTP requests cannot be used. Large online food retail webpages, in specific, have online collections but no application programming interface to directly access their food prices. As a result, the script must use a "real" web browser to navigate and "click “through the website.
In addition, enough time should be set aside for bug fixing and testing. As once script has been written and verified experimentally, its implementation can be fully automated: a scheduler begins the download at predefined time frames. However, changes in a website's layout, product group structure, or other even minor changes can cause the scraper to fail. To really be conscious of such issues, alerts can be built in, such as sending email if a script did not finish completely or if the download size is abnormally small. The data that has been accessed can be stored in any format, such as a text or CSV file, with defined elements (name, ID, price, timestamp, etc.).
The new data for every observation over time are simply added to this file, resulting in a single consistent data set. If several websites (e.g., different retailers or geographic locations) are scraped, separate files can be created, but the formatting should be consistent to facilitate later analysis.

Because many software packages necessarily require daily price data scraping, it is possible that you do not want to occupy your computer with this task. Alternatives include a committed desktop machine, such as the Raspberry Pi, or a private server. If one lacks the technological infrastructure or coding know-how to build one's own solution, commercial web scraping service providers can be used. Such commercial possibilities, even so, may lack the disclosure and open code paperwork needed for the majority of scientific studies and peer-reviewed articles. It may be more appropriate to use and adapt open-source libraries for such purposes.
Which are the Advantages of Web Scraping Price Data?
Web scraping is a successful new method of scraping food data for various food price research. It aids in overcoming some of the limitations of traditional sources of data, such as official figures and scanner data.
Low Prices
Good data pairs can be costly. Access to highly frequent and dispersed data, such as metadata, is particularly expensive at the retail level. Price collection via web scraping is essentially free if completed with open-source software. The time necessary to read and test software is one of the costs associated with web scraping. Electricity and internet access are required when the script is executed at the specified times. With all of this in place, scalability across countries and products is high, effectively lowering the marginal cost per observation to near zero. Alternatively, if funds are available, activities can be subcontracted to a growing number of commercial companies offering Information as a Service.
Frequent and Real-time Sampling

Once the code is published, it's indeed up to the user to decide whether it should run and retrieve prices as well as other information on a monthly, weekly, daily, or even more frequent basis (e.g., hourly, as done by Ellison and Ellison, 2009). For most applications, daily data should suffice for food price research. When compared to the assessment of time-aggregated price information, such a high sampling frequency allows for a more detailed analysis of price dynamics and the application of other statistical methods (Edelman, 2012). Furthermore, because data is collected in real time, there is no publication lag. This is useful for analyzing recent events or policy changes, as well as forecasting.
Product Variety and Details

Consumer prices are generally reported in official statistics at broad product or product category levels. Additional information such as package size, brand, quality differentiation, and so on, which may be useful for food price analysis, are generally unavailable. Web scraping, can be used to extract food prices for particular products, including all available product attributes. This could be useful information for some research questions. If not, using this information as a starting point, the researchers can aggregate the data to the level required, using whatever methods they deem appropriate.
Store Type
The type of store. Most secondary information simply state that they were collected at the "retail level," with distinctions made between supermarkets, discounters, and small single retailer stores. Researchers use web scraping to determine which stores, retailers, wholesalers, or online delivery services they are involved in and collect prices, if obtainable, without any hidden accumulation. Self-identification, such as accessing a postal code or selecting a country, may be required to access various websites in regions and countries and can be included in the web scraper code.
Transparency and Personalization
Although scanner data and many government figures provide incredibly stable and well-structured information, those who may not always contain all of the data that researchers require for their projects. It is possible that this information has been accumulated to some level or that they are not accessible in the same framework or from the same provider for all geographic locations of interest, resulting in limited international similarity.
Restaurant data scraping services facilitate the generation of customized data sets that are tailored to the needs of the user and are transparent in terms of how the data was obtained, with no omitted variables or black boxes. When open-source software is used and code and data are shared, the scientific community gains transparency and reproducibility. Providing researchers with the ability to incorporate data collection into their empirical work rather than relying on secondary data may thus improve the quality and precision of empirical research.
Areas of Research
Several more web scraping requests were used in the past to analyse online pricing for non-food consumer products. Because large-scale online store began with product types such as books and electronic parts, most initial pricing research on the internet concentrated on these products
Scraping Online Retail Pricing Policies
It is commonly assumed that online published valuations are more adaptable than offline costs, which, with the exception of temporary promotions, exhibit rather rigid pricing trends. Menu costs to adjust prices are negligible in online markets, allowing suppliers to adjust prices at a high frequency, reacting to changes in demand and supply, and ultimately leading to more efficient. On the consumer side, price search costs have decreased, and price comparison for a specific good is quick and easy, thanks in part to price comparison websites.
Online retail may even enable pricing structure based on an analysis of present and previous customer requirements, competitor setting prices, and other factors such as holidays or weather patterns. However, detecting such practices would necessitate the use of very innovative web scraping code that pretended to log on from different IP addresses and with different user profiles. Again, the issue is whether it is moral for researchers to collect data under the pretense of a valid user request.
Final Words
We demonstrated that web scraping is a promising and reduced data collection method for food price investigation. Web scraping to create unique data sets can assist in overcoming common issues such as incomplete information, systematic errors, and sampling procedures. Because of their widespread availability, online retail price increases have been the primary application thus far. Information compiled through web scraping can aid in assessing how rates are set in the expanding online food retail market, and how this price fixing may impact the supply chain and possibly alter global food systems.
Furthermore, scraping online prices provide understanding into general (offline) price advancement and can help to fill in gaps where public data sources are unavailable or untrustworthy. As more and more price data are published online, so will the areas of application for web scraping. This method will open up new research opportunities, particularly for global data collection and comparisons.
Exploiting this latest tech helped us to identify real solutions to old questions, as well as ask new ones. Once researchers and practitioners are aware of the technical possibilities, they may create fresh applications. However, we discovered some restrictions that may discourage or inhibit individual experts from engaging in web scraping, such as moral and professional uncertainties, a lack of historical information, and technical difficulties. Working together and consolidating data collection can assist in overcoming these. Larger data collection projects could combine technical and legal expertise and take advantage of web scraping technologies' scalability.
A comparable web data extraction project for food inflation research could be launched, collecting and publishing consistent and cleaned data. After a little time of continuous real-time data gathering, the data could be useful to a wide range of researchers in agricultural production, development studies, and related fields. However, some academic institutions, institutes, or associations would need to take the initiative and make the initial investment. During the first phase, the planners could set up a public data base where researchers can upload and share scraped data sets that may be useful to colleagues who are also interested in food prices. Although competition for the best scripts and the most data may be fruitful in some cases, cooperating and sharing data sources and methods to advance research is likely to result in less unfair and grander sets of data, as well as better outcomes.
If you require more details about how web scraping is used for food price researching, then you can contact Foodspark today or request for a quote!
Know more : https://www.foodspark.io/how-web-scraping-is-used-for-researching-food-price.php




Web scraping is a technique that is used by a number of companies and businesses for extracting information that would be valuable for their business.
By extracting data from a number of different websites can help the businesses in a various ways.
Also, one can easily make sense that the demand of web scraping service is everywhere.Thus in this article you'll find some major reasons so as to why web scraping is leveraged.
So, go through them!Lead generation: Web scraping is popularly known for the purpose of lead generation and contacts for the businesses in a liberal manner.
One can easily collect contact details, email ids and other necessary information through web scraping.Reputation & brand monitoring: With the help of web scraping services, one can easily get boost brand intelligence by a number of ways and also get an idea of different brands in specific demographics.
This would particularly help the business in understanding about how the customers feel about their products and services.Collecting data for machine learning: As machine learning requires large input of data for different purposes, thus web scraping can be effectively used for deriving data for benefiting its progress.Competitor analysis: The web scraping is also useful for extracting data for competitor analysis and for deriving brand analysis in a structured format.






















