







 Web scraping is a potent method for extracting data from the internet, but conducting large-scale scraping operations without encountering blocking issues can be a formidable challenge. In this tutorial, we aim to share valuable insights, tips, and tricks to help you seamlessly scrape Amazon product categories while avoiding detection and blocking.
Web scraping is a potent method for extracting data from the internet, but conducting large-scale scraping operations without encountering blocking issues can be a formidable challenge. In this tutorial, we aim to share valuable insights, tips, and tricks to help you seamlessly scrape Amazon product categories while avoiding detection and blocking.
We will leverage Playwright to scrape Amazon product category, a versatile open-source Python library designed to facilitate web automation and data extraction. Playwright empowers developers to automate web page interactions, enabling data extraction in both headless and visible browser environments. One of its key advantages is cross-browser compatibility, allowing you to test your web scraping scripts across various browsers, including Chrome, Firefox, and Safari. Additionally, Playwright offers robust error handling and retry mechanisms, streamlining the process of overcoming shared web scraping hurdles such as timeouts and network errors.
This tutorial will guide you through scraping cookware data from Amazon using Playwright in Python and saving it as a CSV file. By the end of this tutorial, you will understand how to scrape Amazon product categories without encountering blocking issues and how to effectively employ Playwright to automate web interactions and extract data efficiently.
We will extract a range of data attributes from individual Amazon product pages, including:
Product URL
Product Name: The name of the cookware product
Sale Price
Brand: The brand of the cookware product.
MRP (Maximum Retail Price): The MRP of the cookware product.
Number of Reviews: The number of reviews for the cookware product.
Ratings
Best Sellers Rank: The rank of the cookware products, including Home & Kitchen rank, Air
Technical Details: The technical specifications of the cookware products encompass information like wattage, capacity, color, and more.
About This Item
This tutorial will provide a step-by-step guide for employing Playwright in Python to scrape cookware data from Amazon, ensuring you acquire valuable insights while navigating the intricacies of web scraping.
Import Necessary Libraries
To initiate our process, we must import essential libraries that will facilitate our interaction with the website and enable us to extract the necessary information.
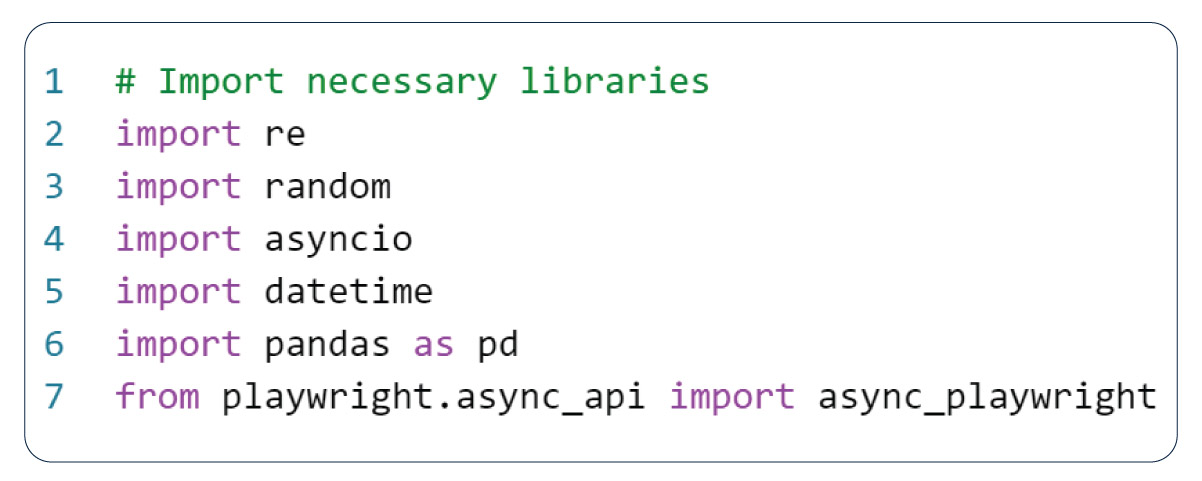 In this script, we have imported various Python modules and libraries essential for our operations:
In this script, we have imported various Python modules and libraries essential for our operations:
re - The 're' module is crucial for working with regular expressions.
Random - The 'random' module generates random numbers, making it useful for tasks such as generating test data or randomizing the order of tests.
asyncio - The 'asyncio' module is indispensable for handling asynchronous programming in Python and is necessary when utilizing Playwright's asynchronous API.
datetime: The 'datetime' module is helpful for various date and time-related operations, including creating and manipulating date and time objects and formatting them into strings.
pandas: The 'pandas' library is a powerful data manipulation and analysis tool. This tutorial helps store and process data obtained from web pages.
async_playwright - The 'async_playwright' module is instrumental in automating web browsers using Playwright. Playwright is an open-source Node.js library renowned for automation testing and web scraping.
These libraries collectively enable us to automate browser testing using Playwright, incorporating functionalities for data management, asynchronous programming, and web browser interaction automation.
Scrape Product URLs
The next step involves the extraction of cookware product URLs. This process entails gathering and structuring the URLs of products listed on a web page or online platform.
Before embarking on the task of scraping product URLs, it's imperative to take several considerations into account to ensure responsible and effective data extraction:
Standardized URL Format: Maintaining a consistent and standardized format for the scraped product URLs is crucial. We can adopt a format like "https://www.amazon.in/+product name+/dp/ASIN," which encompasses the website's domain name, the product name (without spaces), and the unique ASIN (Amazon Standard Identification Number) at the end of the URL. This standardized structure simplifies data organization analysis and ensures URL clarity and consistency.
Filtering Criteria: When scraping data from Amazon for cookware, it's vital to filter the information meticulously. Often, accessories are alongside the leading products in search results. To obtain only relevant data about cookware, applying specific filtering criteria, such as product category or keywords within the product title or description, may be necessary. This filtering process ensures that the extracted data focuses solely on cookware, enhancing its usefulness and relevance.
Handling Pagination: Scraping product URLs may entail navigating multiple pages by clicking on the "Next" button at the bottom of the webpage. However, challenges can arise if clicking the "next" button fails to load the subsequent page, potentially causing errors in the scraping process. Implementing error-handling mechanisms like timeouts, retries, and checks is essential to mitigate this. These safeguards ensure that each page is fully loaded before data extraction, enhancing the effectiveness and efficiency of the scraping process while respecting the website's resources.
By considering these points and implementing responsible scraping practices, we can extract product URLs in a manner that ensures data quality, relevance, and accuracy.
 In this section, we employ the Python function 'get_product_urls' to systematically gather product links from a web page. Leveraging the Playwright library, this function automates browser testing, allowing us to extract the resultant Amazon product URLs effectively.
In this section, we employ the Python function 'get_product_urls' to systematically gather product links from a web page. Leveraging the Playwright library, this function automates browser testing, allowing us to extract the resultant Amazon product URLs effectively.
The core functionality of the function revolves around identifying whether a "next" button exists on the page. When detected, the function triggers a click on this button and recursively invokes itself to extract URLs from subsequent pages. This iterative process continues until all pertinent product URLs are collected.
Here's a breakdown of how the function operates:
Selection of Product Elements: The function begins by selecting all webpage elements containing product links, utilizing a CSS selector.
Storage of Unique URLs: Initialize an empty set to store unique product URLs.
Iteration through Elements: The function iterates through each selected element, extracts the 'href' attribute, and performs a series of operations to refine the link. It includes cleansing the URL based on specific conditions and eliminating undesired substrings such as "Basket" and "Accessories."
Cleaning and Filtering: After cleaning the URL, the function checks whether it contains unwanted substrings. If none are present, the cleaned URL is available to the set of product URLs.
Final Collection: Ultimately, the function returns the list of unique product URLs as comprehensible.
Through these steps, the 'get_product_urls' function effectively extracts and refines product URLs from the web page, ensuring data accuracy and relevance while filtering out unwanted information.
Amazon Cookware Data Extraction
In this phase, we will define the attributes we aim to retrieve from the website. Our extraction targets include the Product Name, Brand, Number of Reviews, Ratings, Maximum Retail Price (MRP), Sale Price, Best Sellers Rank, Technical Details, and
About the Amazon cookware product.
Extraction of Product Name
The subsequent task involves the extraction of product names from the respective web pages. Product names hold significant importance as they give customers a rapid overview of each product, including its features and intended use. The objective at this stage is to identify and select the elements within a web page that contain the product name and extract the textual content from these elements.
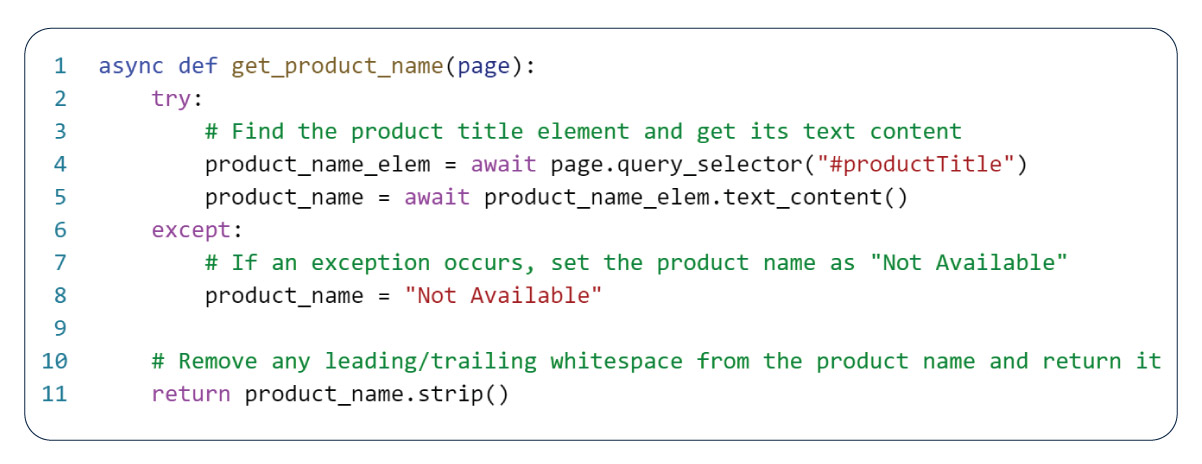 To extract product names from web pages, we use the function 'get_product name,' which is available on a single page object. The function first locates the product's title element on the page by calling the page object's 'query_selector()' method and passing in the appropriate CSS selector. Once the element is available, the function employs the 'text_content()' method to retrieve the element's text content, which is available in the 'product_name' variable.
To extract product names from web pages, we use the function 'get_product name,' which is available on a single page object. The function first locates the product's title element on the page by calling the page object's 'query_selector()' method and passing in the appropriate CSS selector. Once the element is available, the function employs the 'text_content()' method to retrieve the element's text content, which is available in the 'product_name' variable.
When the function cannot find or retrieve a particular item's product name, it handles exceptions by setting the product name to "Not Available" in the 'product_name' variable. This approach ensures that our web scraping code can continue running despite encountering unexpected errors during data extraction.
Extracting Brand Name
When it comes to web scraping eCommerce data, extracting the brand's name associated with a particular product is essential in identifying the manufacturer or company that produces the product. The process of extracting brand names is similar to product names - we search for the relevant elements on the page using a CSS selector and then extract the text content from those elements.
However, brand information may appear on the page in a couple of different formats. For instance, the brand name might be available by the text "Brand: 'brand name,'" or appear as "Visit the 'brand name' Store." To extract the brand's name accurately, we must filter out these extraneous elements and retrieve only the actual brand name.
We can use regular expressions or string manipulation functions in our web scraping code to achieve this. By filtering out the unnecessary text and extracting only the brand name, we can ensure our brand extraction process is accurate and efficient.
 To extract the brand name from web pages, we employ a function similar to the one used for extracting the product name. In this case, the function is named 'get_brand_name' and operates by attempting to locate the element containing the brand name using a CSS selector.
To extract the brand name from web pages, we employ a function similar to the one used for extracting the product name. In this case, the function is named 'get_brand_name' and operates by attempting to locate the element containing the brand name using a CSS selector.
When the element is successfully available, the function extracts the text content from that element using the 'text_content()' method and assigns it to a 'brand_name' variable. It's worth noting that the extracted text may contain extra information, such as "Visit," "the," "Store," and "Brand," which eliminates the use of regular expressions.
We can obtain the genuine brand name by filtering out these unnecessary words, ensuring data accuracy. If the function encounters an exception while attempting to locate the brand name element or extracting its text content, it gracefully returns the brand name as "Not Available."
By incorporating this function into our web scraping script, we can efficiently extract the brand names of the products of interest, providing valuable insights into the manufacturers and companies associated with these products.
Similarly, we can apply the same technique to extract attributes such as MRP and Sale Price.
Extracting MRP of the Products
Accurately assessing a product's value necessitates the extraction of its Manufacturer's Retail Price (MRP) from the corresponding web page. This information is crucial for retailers and customers, enabling them to make informed purchasing decisions. The process of extracting the MRP of a product mirrors that of extracting the product name.
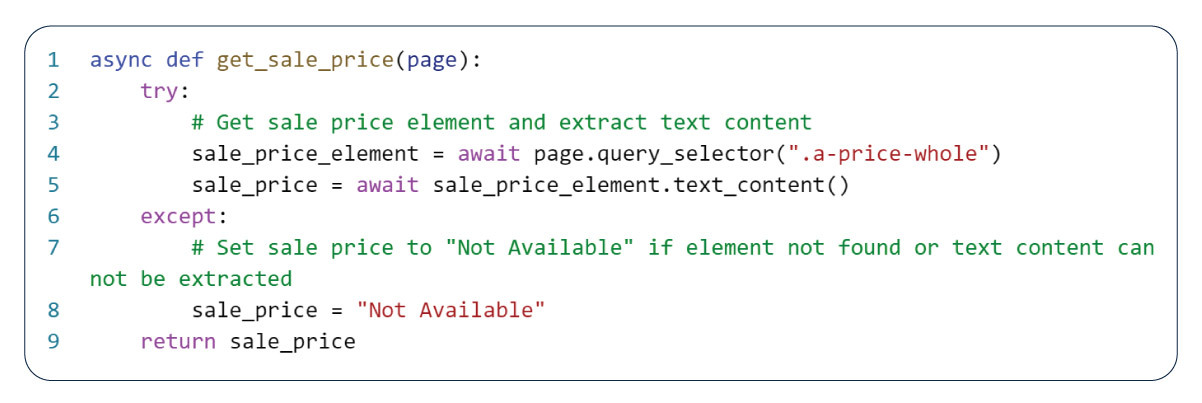
 Extracting the Sale Price of the Products
Extracting the Sale Price of the Products
The sale price of a product plays a pivotal role in aiding customers in making informed purchasing decisions. Extracting the sale price from a webpage empowers customers to effortlessly compare prices across various platforms and identify the most advantageous deal. This information holds significant value for budget-conscious shoppers seeking to maximize their expenditure and secure the best possible value for their money.
Extracting Product Ratings
The next crucial step in our data extraction process involves procuring the star ratings assigned to each product from their respective web pages. These ratings, typically provided by customers on a scale of 1 to 5 stars, offer valuable insights into the product's quality and user satisfaction. However, it's essential to acknowledge that not all products will possess ratings or reviews. In such instances, the website may indicate that the product is "New to Amazon" or has "No Reviews." Several factors may contribute to this absence, including limited availability, low popularity, or the product's novelty in the market without customer reviews. Nevertheless, extracting star ratings is a pivotal component in assisting customers in making well-informed purchasing decisions.
 To extract the star rating of a product from a web page, we employ the 'get_star_rating' function. Initially, this function attempts to pinpoint the page's star rating element by utilizing a CSS selector that accurately identifies the element containing the star ratings. This task uses the 'page.wait_for_selector()' method. Once the element is successfully available, the function proceeds to extract the inner text content of the element, achieved through the 'star_rating_elem.inner_text()' method.
To extract the star rating of a product from a web page, we employ the 'get_star_rating' function. Initially, this function attempts to pinpoint the page's star rating element by utilizing a CSS selector that accurately identifies the element containing the star ratings. This task uses the 'page.wait_for_selector()' method. Once the element is successfully available, the function proceeds to extract the inner text content of the element, achieved through the 'star_rating_elem.inner_text()' method.
When an exception arises while locating the star rating element or extracting its text content, the function adopts an alternative approach to verify if no reviews are available for the product. To accomplish this, it endeavors to locate the element bearing the ID that signifies the absence of reviews, utilizing the 'page.query_selector()' method. Upon successful location of this element, the text content of said element is available to the 'star_rating' variable.
Should both of these attempts prove unsuccessful, the function enters the second exception block and designates the star rating as "Not Available" without further attempts to extract any rating information. This design ensures explicit notification to the user regarding the unavailability of star ratings for the product.
Extracting the Number of Reviews for the Products
Extracting the number of reviews for each product is pivotal in gauging product popularity and customer satisfaction levels. The number of reviews is indicative, representing the cumulative feedback and ratings customers provide for a specific product. This information equips potential buyers with valuable insights, enabling them to make well-informed purchasing decisions and grasp the extent of satisfaction or dissatisfaction expressed by previous purchasers.
Nevertheless, it's essential to acknowledge that not all products may possess reviews. The website may display indicators such as "No Reviews" or "New to Amazon" instead of specifying the number of reviews on the product page. Several factors can contribute to this absence, including the product's novelty in the market, a lack of customer reviews due to limited availability, low popularity, or other relevant considerations.
 The function 'get_num_reviews' plays a pivotal role in extracting the number of reviews for products from web pages. Initially, the function endeavors to locate an element containing the review count by applying a CSS selector that precisely targets the element bearing the ID housing this information. If this quest proves successful, the function extracts the text content through the 'inner_text' method, storing it within a variable named 'num_reviews.'
The function 'get_num_reviews' plays a pivotal role in extracting the number of reviews for products from web pages. Initially, the function endeavors to locate an element containing the review count by applying a CSS selector that precisely targets the element bearing the ID housing this information. If this quest proves successful, the function extracts the text content through the 'inner_text' method, storing it within a variable named 'num_reviews.'
However, in cases where the initial attempt yields no results, the function adopts an alternative strategy: it strives to identify an element that signifies the absence of reviews for the product. Upon locating such an element, it employs the 'inner_text()' method to extract its text content, assigning it to the 'num_reviews' variable. In scenarios where both attempts fall short, the function gracefully returns "Not Available" as the value of 'num_reviews,' signifying that the review count was not on the web page.
It's essential to recognize that not all products will have reviews, owing to various factors such as their newness to the market, limited availability, or low popularity. Nevertheless, the review count serves as valuable information capable of offering insights into a product's popularity and customer satisfaction.
Extracting Best Sellers Rank Of The Products
The extraction of the Best Sellers Rank represents a crucial step in assessing product popularity and sales performance on online marketplaces, including Amazon. This metric, the Best Sellers Rank, is Amazon's method for ranking product popularity within their respective categories. It undergoes hourly updates and considers multiple factors, including recent sales, customer reviews, and ratings. The rank is a numerical value, with lower numbers indicative of higher popularity and greater sales volume.
For instance, when extracting the Best Sellers Rank for cookware products, two distinct values can be obtained: the Home and Kitchen rank and the cookware rank contingent on the product's category. The extraction of the Best Sellers Rank equips us with invaluable insights into product performance within the market. This information empowers customers to select products with popularity and positive reviews, enabling them to make well-informed purchasing decisions.
![]() The function 'get_best_sellers_rank' is pivotal in extracting Best Sellers Rank data from web pages. Initially, it endeavors to locate the Best Sellers Rank element on the page by utilizing a precise CSS selector that targets the 'td' element following a 'th' element containing the text "Best Sellers Rank." Upon locating this element, the function employs the 'text_content()' method to extract its text content, assigning it to the 'best_sellers_rank' variable.
The function 'get_best_sellers_rank' is pivotal in extracting Best Sellers Rank data from web pages. Initially, it endeavors to locate the Best Sellers Rank element on the page by utilizing a precise CSS selector that targets the 'td' element following a 'th' element containing the text "Best Sellers Rank." Upon locating this element, the function employs the 'text_content()' method to extract its text content, assigning it to the 'best_sellers_rank' variable.
Subsequently, the code delves into a loop that handles each rank and directs the respective rank to the appropriate variable. It ensures that if the rank includes the string "in Home & Kitchen," it is allocated to the 'home_kitchen_rank' variable. Similarly, if the rank encompasses the strings "in cookware", it is assigned to the 'cook_ware_rank' variable. These variables provide insights into the product's popularity within its specific category.
However, in instances where the Best Sellers Rank element eludes detection on the page, the function takes a graceful approach by assigning the value "Not Available" to both the 'home_kitchen_rank' and 'cook_ware_rank' variables, signifying that the rank information could not be available from the page.
![]() The 'get_technical_details' function is instrumental in extracting technical information from web pages, facilitating informed purchase decisions for customers. This function takes a webpage object as input and yields a dictionary containing technical details retrieved from the page. Its process involves initially attempting to locate the technical details table using its unique ID and extracting each row within the table as a list of elements. Subsequently, the function iterates through these rows, extracting key-value pairs for each technical specification.
The 'get_technical_details' function is instrumental in extracting technical information from web pages, facilitating informed purchase decisions for customers. This function takes a webpage object as input and yields a dictionary containing technical details retrieved from the page. Its process involves initially attempting to locate the technical details table using its unique ID and extracting each row within the table as a list of elements. Subsequently, the function iterates through these rows, extracting key-value pairs for each technical specification.
Furthermore, utilizing their respective keys, the function captures specific technical details such as color, capacity, wattage, and country of origin. In cases where the value for any of these technical aspects is "Not Available" or "default," the function conducts additional searches to locate the corresponding element on the webpage and retrieve its inner text. If successful, it returns the specific value; otherwise, it defaults to "Not Available."
The extraction of the "About this item" section from product web pages serves as a crucial step in presenting a concise overview of the product's essential features, advantages, and specifications. This information equips potential buyers with a clear understanding of the product's purpose, functionality, and differentiating factors compared to similar offerings. It aids buyers in making product comparisons and evaluating whether the specific product aligns with their requirements and preferences. Extracting this information from product listings is pivotal for fostering informed purchase decisions and ensuring customer satisfaction.
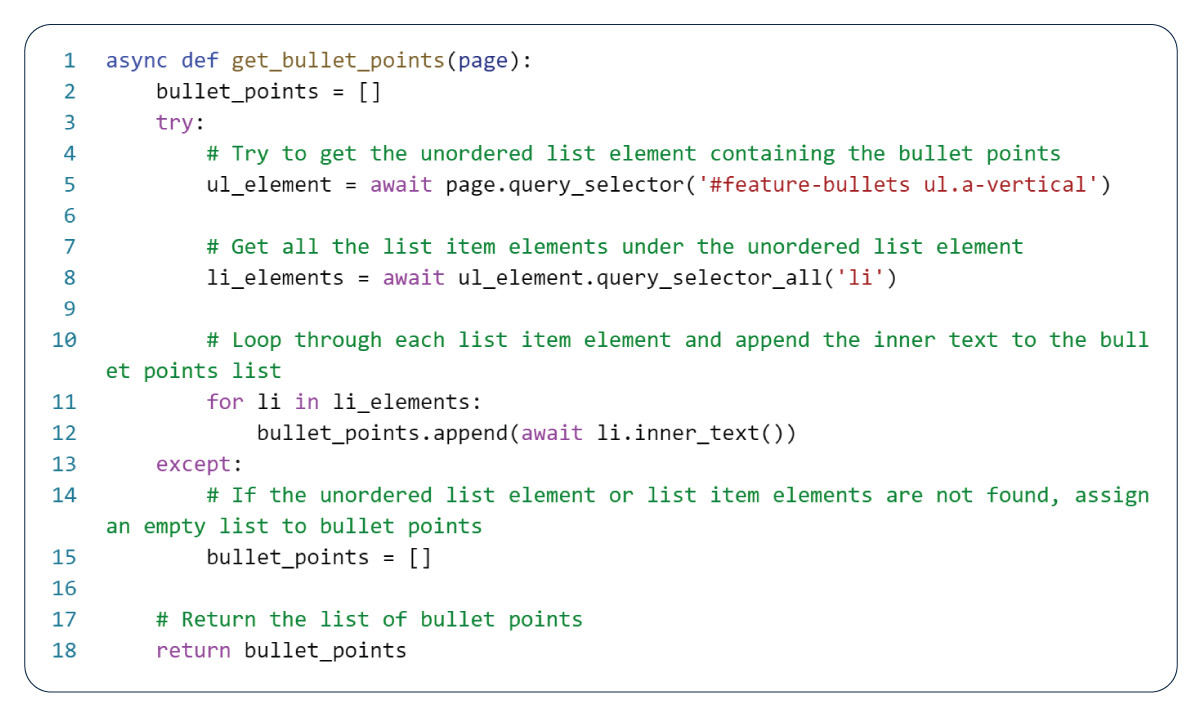
 The 'get_bullet_points' function extracts bullet point information from web pages. Its operation commences with an attempt to locate an unordered list element containing bullet points. It is available using a CSS selector to target the 'About this item' element with a specific ID. Should the unordered list element about 'About this item' be successfully located, the function retrieves all the list item elements nested beneath it, employing the 'query_selector_all()' method. Subsequently, the function iterates through each list item element, appending its inner text to the bullet points list. When exceptions arise while locating the unordered list element or its associated list item elements, the function sets the bullet points as an empty list. Ultimately, the function returns the compiled list of bullet points.
The 'get_bullet_points' function extracts bullet point information from web pages. Its operation commences with an attempt to locate an unordered list element containing bullet points. It is available using a CSS selector to target the 'About this item' element with a specific ID. Should the unordered list element about 'About this item' be successfully located, the function retrieves all the list item elements nested beneath it, employing the 'query_selector_all()' method. Subsequently, the function iterates through each list item element, appending its inner text to the bullet points list. When exceptions arise while locating the unordered list element or its associated list item elements, the function sets the bullet points as an empty list. Ultimately, the function returns the compiled list of bullet points.
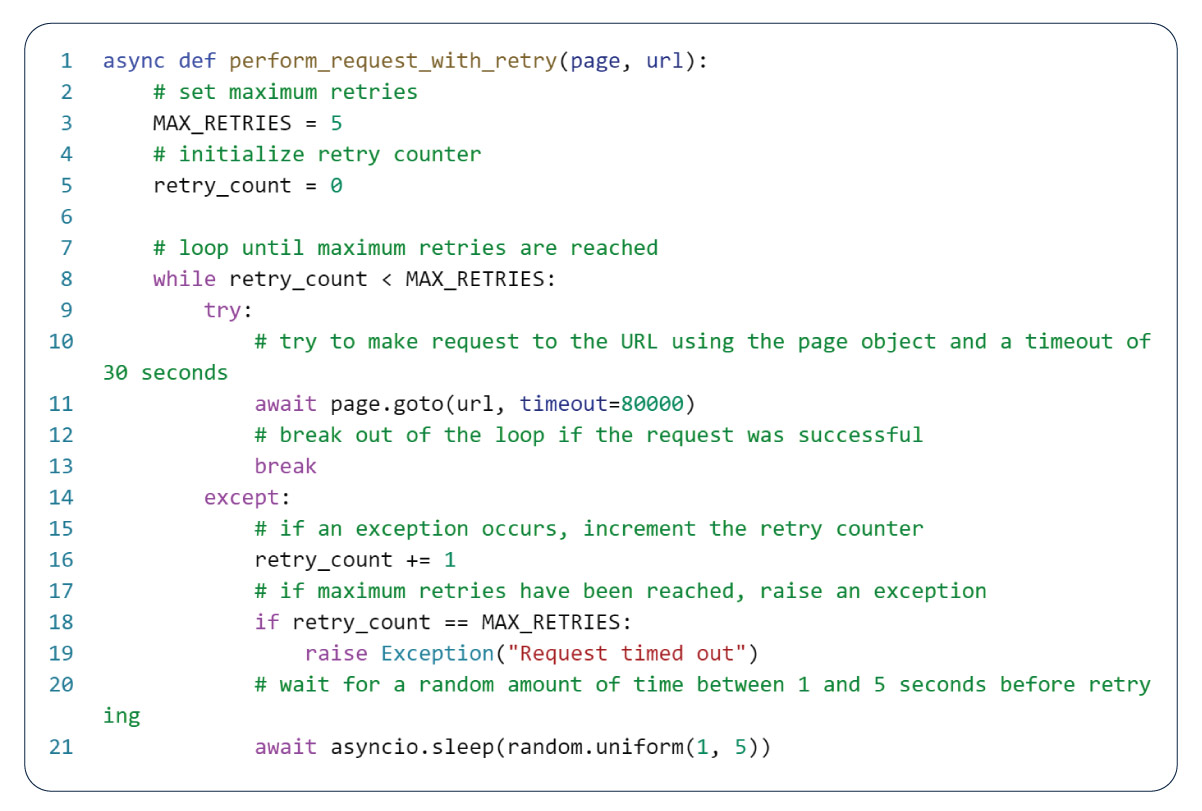
Including request retry functionality with a maximum retry limit is a vital component of web scraping. It addresses temporary network errors or unexpected website responses, increasing the likelihood of successful requests. Before navigating to the specified URL, the script provide a retry mechanism to handle request timeouts. This mechanism is through a while loop that persists in attempting to navigate to the URL until either the request succeeds or the maximum permissible number of retries is exhausted. The script triggers an exception if the maximum number of retries is without success. This code represents a function designed to execute a request to a given link, with built-in retry capabilities in case of request failures. Such functionality is invaluable when web scraping operations, as request failures can occur due to network issues or timeouts.
 The 'perform_request_with_retry' function operates asynchronously and initiates a request to a specified URL via a page object. Within its loop structure, the function repeatedly endeavors to execute the URL request using the 'page.goto()' method, allotting a timeout duration of 30 seconds. The loop is available if the request proves successful and the function terminates. In cases where exceptions arise during the request attempt, such as timeouts or network errors, the function reattempts the request, subject to the defined maximum number of retries. The maximum number of retries is by the MAX_RETRIES constant, which is five. If the maximum allowable number of retries is exhausted, the function raises an exception, accompanied by the message "Request timed out." However, if the maximum number of retries is unavailable, the function pauses for a random duration between 1 and 5 seconds, leveraging the asyncio.sleep() method before initiating a subsequent retry of the request.
The 'perform_request_with_retry' function operates asynchronously and initiates a request to a specified URL via a page object. Within its loop structure, the function repeatedly endeavors to execute the URL request using the 'page.goto()' method, allotting a timeout duration of 30 seconds. The loop is available if the request proves successful and the function terminates. In cases where exceptions arise during the request attempt, such as timeouts or network errors, the function reattempts the request, subject to the defined maximum number of retries. The maximum number of retries is by the MAX_RETRIES constant, which is five. If the maximum allowable number of retries is exhausted, the function raises an exception, accompanied by the message "Request timed out." However, if the maximum number of retries is unavailable, the function pauses for a random duration between 1 and 5 seconds, leveraging the asyncio.sleep() method before initiating a subsequent retry of the request.
The subsequent step entails invoking these functions and accumulating the retrieved data into an initially empty list.
 In this Python script, we have utilized an asynchronous function called "main" to extract product information from Amazon pages. The script employs the Playwright library to launch the Firefox browser and navigate to the Amazon page. Subsequently, the "extract_product_urls" function extracts the URLs of each product from the page and stores them in a list called "product_url." The function then loops through each product URL. It uses the "perform_request_with_retry" function to load the product page and extract various information such as the product name, brand, star rating, number of reviews, MRP, sale price, best sellers rank, technical details, and descriptions.
In this Python script, we have utilized an asynchronous function called "main" to extract product information from Amazon pages. The script employs the Playwright library to launch the Firefox browser and navigate to the Amazon page. Subsequently, the "extract_product_urls" function extracts the URLs of each product from the page and stores them in a list called "product_url." The function then loops through each product URL. It uses the "perform_request_with_retry" function to load the product page and extract various information such as the product name, brand, star rating, number of reviews, MRP, sale price, best sellers rank, technical details, and descriptions.
The resulting data is in a tuple in a list called "data." The function also provides progress messages after processing every 10 product URLs and a completion message after all the product URLs have been available. The data is then converted to a Pandas DataFrame and saved as a CSV file using the "to_csv" method. Finally, the browser is closed using the "browser.close()" statement. Execute the script by calling the "main" function using the "asyncio.run(main())" statement, which runs the "main" function as an asynchronous coroutine.
Conclusion: This comprehensive guide provides a detailed, step-by-step walkthrough of scraping Amazon cookware data using Playwright in Python. Our guide covers the entire spectrum of tasks, starting from the initial setup of the Playwright environment and launching a web browser to navigating to Amazon's search page and efficiently extracting crucial data such as product names, brands, star ratings, MRP, sale prices, bestseller ranks, technical details, and bullet points.
Our instructions are user-friendly, ensuring you can easily extract product URLs, iterate through each URL, and utilize Pandas to organize the extracted data into a structured data frame. Thanks to Playwright's cross-browser compatibility and robust error-handling capabilities, users can effectively automate the web scraping process and extract valuable insights from Amazon listings.
Web scraping can often be a laborious and time-intensive task. Still, with Playwright Python, you have a powerful tool at your disposal to automate these tasks, ultimately saving time and effort. By following our guide, you'll be well-equipped to embark on web scraping endeavors, enabling you to make informed purchasing decisions, conduct thorough market research, and gain valuable insights into the dynamic realm of e-commerce. Playwright Python is an indispensable asset for anyone seeking to harness the potential of web scraping in the modern digital landscape.
Product Data Scrape is committed to upholding the utmost standards of ethical conduct across our Competitor Price Monitoring Services and Mobile App Data Scraping operations. With a global presence across multiple offices, we meet our customers' diverse needs with excellence and integrity.
Know More:
https://www.productdatascrape.com/scrape-amazon-product-category-without-getting-blocked.php



Other e-commerce sectors will scrape information from Amazon, which is the most popular e-commerce website.
Price, pictures, ASIN, BSR, specifications, descriptions, and ratings/reviews for a variety of products will all be scraped from Amazon using Amazon product data scraper.Because Amazon uses different page layouts for different products and the number of details available will differ.
The Capture Following Text Technique will extract Amazon product information exactly from the product details description.This will aid in receiving data about a header text, regardless of its location on the page.
This is used to select product data such as ASIN, price, and shopping weight, among other things.The Amazon product scraped data will be saved as a local file in CSV, TSV, XML, JSON, or another format, or it will be saved to a database.
The amount of data that can be extracted or imported is limitless.
It will be simple to extract listings that span multiple pages.

We can extract information that is available for Amazon Product Data Scraping for the result page information is available on each of the product pages.What is Amazon & Web Scraping?Web Scraping allows you to select what you want from the Amazon website into spreadsheets or JSON files.
You can easily make an automated process that runs on a daily, weekly, or monthly basis for continuous update of your data.Scrape Product Details from Amazon Product PageThe Amazon Data Extractor will scraper the list of Data Fields for the Following from the product page.Product Name Price Short Description Full Product Description Image URLs Rating Number of Reviews Variants ASINs Sales Rank Link to all Reviews PageScrape Product Amazon Search Result PageAmazon search result page scraper will scrape the following details from the search result page.Product Name Price URL Rating Number of ReviewsWhich step you should take if you block while scraping AmazonWe are adding this extra topic about what if you get block while Scraping Amazon.
Amazon is very likely to flag you as a “BOT” if you will start scraping hundreds of pages using the code above.
How to do that?It’s being said that Mimic human behavior as possible.We are not taking any guarantee that you will not be blocked.
It looks like a human making request for Amazon.com through IP Addresses or proxies.
If you are scraping around 100 pages per minute, then we need about 100/5= 20 proxies.Reduce Number of ASINs Scraped Per MinuteIn this, you can slow down the Scraping Process so that Amazon gives a fewer chance of flagging you as a bot.

Amazon helps you to provide services for the Prime Members.
Moreover, you can do competitor research, shopping comparison, or built an API for the project's app.Web Scraping helps you to easily solve data.Amazon product data scraping assists you to choose specific data you need to wish from the Amazon site from Spreadsheet or JSON file.
You can easily make an automated process, which runs on a weekly, daily, or monthly basis by updating data constantly.Amazon Web Scraping SolutionsAt Web Screen Scraping, we help you to provide complete solutions for Amazon web scraping like images, product features, names, and many more required details.To scrape data from Amazon, you need experience & professionals for putting up all the efforts in and logical manner.
From the big retail organizations, we constantly helping them in preparing directory, doing market research, as well as inventories of the most current products via tool for Scraping Amazon Product Listings.Finest & Structured Data for Amazon Data ScrapingObtaining Amazon Product datasets & directories, which are the latest, accurate, and scraped.
We help you to provide your customization features for scraping Amazon prices with product listing.
Web Screen Scraping, which helps to grow business provides quotes and competitive prices for the finest option.Why A Business Organization needs Amazon Scraper Tool?Amazon Data Scraper collects important data about the products like technical details, price range, sales rank, ASIN, etc.

The Global PVC Window Profile Market Research Report - Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 gives an evaluation of the market developments based on historical studies and comprehensive research respectively.
The market segments are also provided with an in-depth outlook of the competitive landscape and a listing of the profiled key players.The comprehensive value chain analysis of the market will assist in attaining better product differentiation, along with detailed understanding of the core competency of each activity involved.
The market attractiveness analysis provided in the report aptly measures the potential value of the market providing business strategists with the latest growth opportunities.The report classifies the market into different segments based on type and application.
These segments are studied in detail incorporating the market estimates and forecasts at regional and country level.
The segment analysis is useful in understanding the growth areas and probable opportunities of the market.Final Report will cover the impact of COVID-19 on this industry.Browse the complete Global PVC Window Profile Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 @ https://www.decisiondatabases.com/ip/53045-pvc-window-profile-market-reportThe report also covers the complete competitive landscape of the global PVC Window Profile market with company profiles of key players such as:Alphacan SpAAluplast GmbHDeceuninckEpwin GroupEurocellPiva GroupProfine GroupRehauSalamanderSchucoVEKASEGMENTATIONS IN THE REPORT:By TypeTurn & Tilt WindowsSliding WindowCasement WindowOthersBy ApplicationResidentialCommercialBy Geography:North America (NA) – US, Canada, and MexicoEurope (EU) – UK, Germany, France, Italy, Russia, Spain & Rest of EuropeAsia-Pacific (APAC) – China, India, Japan, South Korea, Australia & Rest of APACLatin America (LA) – Brazil, Argentina, Peru, Chile & Rest of Latin AmericaMiddle East and Africa (MEA) – Saudi Arabia, UAE, Israel, South AfricaDownload Free Sample Report of Global PVC Window Profile Market @ https://www.decisiondatabases.com/contact/download-sample-53045The Global PVC Window Profile Market has been exhibited in detail in the following chapters –Chapter 1 PVC Window Profile Market PrefaceChapter 2 Executive SummaryChapter 3 PVC Window Profile Industry AnalysisChapter 4 PVC Window Profile Market Value Chain AnalysisChapter 5 PVC Window Profile Market Analysis By TypeChapter 6 PVC Window Profile Market Analysis By ApplicationChapter 7 PVC Window Profile Market Analysis By GeographyChapter 8 Competitive Landscape Of PVC Window Profile CompaniesChapter 9 Company Profiles Of PVC Window Profile IndustryPurchase the complete Global PVC Window Profile Market Research Report @ https://www.decisiondatabases.com/contact/buy-now-53045Other Reports by DecisionDatabases.com:Global PVC Modifier Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Polyvinyl Chloride (PVC) Resins Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Polyvinyl Chloride (PVC) Films Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026About-Us:DecisionDatabases.com is a global business research reports provider, enriching decision makers and strategists with qualitative statistics.
DecisionDatabases.com is proficient in providing syndicated research report, customized research reports, company profiles and industry databases across multiple domains.Our expert research analysts have been trained to map client’s research requirements to the correct research resource leading to a distinctive edge over its competitors.

The Global Polyvinyl Alcohol Fibers Market Research Report - Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 gives an evaluation of the market developments based on historical studies and comprehensive research respectively.
The market segments are also provided with an in-depth outlook of the competitive landscape and a listing of the profiled key players.The comprehensive value chain analysis of the market will assist in attaining better product differentiation, along with detailed understanding of the core competency of each activity involved.
The market attractiveness analysis provided in the report aptly measures the potential value of the market providing business strategists with the latest growth opportunities.The report classifies the market into different segments based on product type and application.
These segments are studied in detail incorporating the market estimates and forecasts at regional and country level.
The segment analysis is useful in understanding the growth areas and probable opportunities of the market.Final Report will cover the impact of COVID-19 on this industry.Browse the complete Global Polyvinyl Alcohol Fibers Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026 @ https://www.decisiondatabases.com/ip/52885-polyvinyl-alcohol-fibers-market-reportThe report also covers the complete competitive landscape of the global Polyvinyl Alcohol Fibers market with company profiles of key players such as:Anhui Wanwei Group Co., Ltd.E.
I. du Pont de Nemours and CompanyEastman Chemical CompanyKuraray Co. Ltd.Nippon Synthetic Chemical Industry Co.Sekisui Chemical Co. Ltd.Sinopec Sichuan VinylonSEGMENTATIONS IN THE REPORT:By Product TypeFilament FiberStapleOtherBy ApplicationCement AdditivesTextileNon-Woven FabricBy Geography:North America (NA) – US, Canada, and MexicoEurope (EU) – UK, Germany, France, Italy, Russia, Spain & Rest of EuropeAsia-Pacific (APAC) – China, India, Japan, South Korea, Australia & Rest of APACLatin America (LA) – Brazil, Argentina, Peru, Chile & Rest of Latin AmericaMiddle East and Africa (MEA) – Saudi Arabia, UAE, Israel, South AfricaDownload Free Sample Report of Global Polyvinyl Alcohol Fibers Market @ https://www.decisiondatabases.com/contact/download-sample-52885The Global Polyvinyl Alcohol Fibers Market has been exhibited in detail in the following chapters –Chapter 1 Polyvinyl Alcohol Fibers Market PrefaceChapter 2 Executive SummaryChapter 3 Polyvinyl Alcohol Fibers Industry AnalysisChapter 4 Polyvinyl Alcohol Fibers Market Value Chain AnalysisChapter 5 Polyvinyl Alcohol Fibers Market Analysis By Product TypeChapter 6 Polyvinyl Alcohol Fibers Market Analysis By ApplicationChapter 7 Polyvinyl Alcohol Fibers Market Analysis By GeographyChapter 8 Competitive Landscape Of Polyvinyl Alcohol Fibers CompaniesChapter 9 Company Profiles Of Polyvinyl Alcohol Fibers IndustryPurchase the complete Global Polyvinyl Alcohol Fibers Market Research Report @ https://www.decisiondatabases.com/contact/buy-now-52885Other Reports by DecisionDatabases.com:Global Nanofibers Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Glass Fibers Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026Global Optical Fibers Market Research Report – Industry Analysis, Size, Share, Growth, Trends and Forecast Till 2026About-Us:DecisionDatabases.com is a global business research reports provider, enriching decision makers and strategists with qualitative statistics.



















